 Comunidad de Sitios de Recursos Documentarios para una Democracia Mundial
Comunidad de Sitios de Recursos Documentarios para una Democracia Mundial
«Scrutarizar un sitio» en la jerga del equipo de la Coderem significa poner en marcha el proceso automático de extracción de los metadatos de un sitio en formato ScrutariData con el objetivo de permitir al servidor Scrutari incluir el sitio dentro de los resultados de búsqueda.
La (…)
 Scrutari
Scrutari
Scrutari es un motor de búsqueda sobre los metadatos (título, subtítulo, autores, palabras clave, etc.) de los diferentes sitios participantes de la Coredem. Es al mismo tiempo herramienta de mutualización (los datos son reunidos en un solo sitio) y de valorización (los resultados de la búsqueda redirigen a los sitios participantes).
La mutualización de datos funciona siguiendo un mecanismo cercano a la recopilación de contenidos: cada sitio participante proporciona un fichero que contiene los metadatos de sus documentos en formato XML denominado ScrutariData. El servidor Scrutari reúne esos datos regularmente para actualizarla como lo muestra el siguiente esquema:
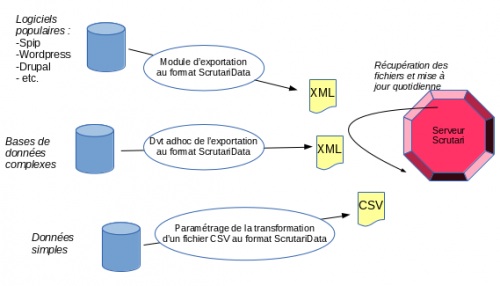
La valorización de los datos se hace por intermedio de «clientes» (como el disponible en este sitio mediante la función «Búsqueda Scrutari») que presentan las búsquedas de los internautas al servidor Scrutari: este último reenvía entonces los resultados en un formato bruto (en términos técnicos, mediante API al formato JSON) que el cliente se encarga de definir su formato.
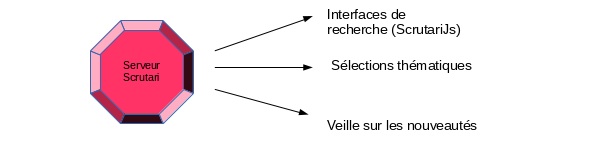
La búsqueda puede ser simple (un solo campo de texto libre) o avanzada con filtros y opciones de búsqueda, como propone el cliente ScutariJs.
Otras formas de valorización están disponibles como los flujos de recopilación para seguir las novedades de los diferentes sitios.
Scrutari es un software libre desarrollado en Java. Su documentación técnica está disponible en el sitio scrutari.net. Scrutari no se limita sólo a la Coderem. También es utilizado en bases internas o se adapta a sitios de recursos particulares.

