 Community of Sites of Documentary Resources for a Global Democracy
Community of Sites of Documentary Resources for a Global Democracy
“Scrutarising a site” is, in Coredem speak, to instigate the automatic process of extracting metadata from a site, formatted in ScrutariData, to allow the Scrutari server to include the site in its search results.
The “scrutarisation” of one’s site is an important step for a Coredem member. It (…)
 Scrutari
Scrutari
Scrutari is a metadata search engine (title, subtitle, author, keywords, etc.) common to the different sites which are part of Coredem. It is both a sharing tool (data is pooled in one place) and a promotion tool (search results are redirected to other participating sites).
The sharing of data works in a similar way to content syndication: each participating site provides a file with its documents’s metadata under an XML format called ScrutariData. The Scrutari server regularly collects data in order to update its searches, as illustrated in the diagram below:
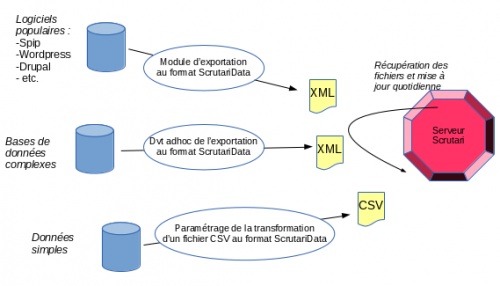
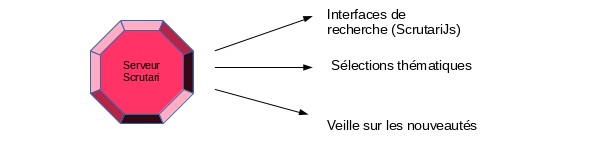
Data retrieval is done through "clients" (such as that available on this site using the “Search Scrutari” function), which submit internet user’s searches to the Scrutari server. The latter then returns results in a raw format (in technical terms, via an API in JSON format) which can then be formatted by the client.
A search can be quick (one free text box) or can include advanced filters and search options, as with the client ScutariJs.
Other forms of data retrievals are available, such as syndication feeds, which provide updates of newly published content on other sites.
Scrutari is a free software written in Java. The technical documentation is available on the website scrutari.net. Scrutari is not only used by the Coredem. It is also used for internal databases and has been adapted to specific resource websites.

